Before we classify the representations of SU(3), I want to introduce a representation which makes sense for any Lie group, the adjoint representation, and study it for SU(3).
Definition:
Given a matrix group G with Lie algebra little g, the adjoint representation is the homomorphism capital Ad from big G to big G L of little g defined by capital Ad of g applied to X equals g X g inverse. In other words:
the vector space on which we're acting is little g,
capital Ad of g is a linear map from little g to little g.
It is an exercise to check that this is a representation, but I will explain why it is well-defined, in other words why is g X g inverse in little g when X is in little g and g is in big G.
Lemma:
If X is in little g and g is in big G then g X g inverse is in little g.
Proof:
We need to show that for all t in R, exp of t g X g inverse is in G. As a power series, this is: exp of (t g X g inverse) equals the identity, plus t g X g inverse, plus a half t squared g X g inverse g X g inverse, plus dot dot dot.
All of the g inverse gs sandwiched between the Xs cancel and we get identity, plus t g X g inverse, plus a half t squared g X squared g inverse, plus dot dot dot.
Since g is in G, g inverse is in G and exp of (t X) is in G for all t, we see that this product is in G for all t, which proves the lemma.
Definition:
The induced map on Lie algebras is little ad equals capital Ad star from little g to little g l of little g. (I apologise for the profusion of g's playing different notational roles).
Let's calculate little ad of X for some X in little g. This is a linear map little g to little g, so let's apply it to some Y in little g: little ad of X applied to Y is the derivative with respect to t at t = 0 of capital Ad of exp (tX) applied to Y (This is how we calculate R star for any representation R: it follows by differentiating R of exp (t X) equals exp of t R star X with respect to t). This gives: little ad of X applied to Y equals the derivative with respect to to at t = 0 of (exp t X times Y times exp of minus t X, which equals (X exp (t X) Y exp (minus t X) minus exp (t X) times Y times X times exp of (minus t X), all evaluated at t=0, which gives X Y minus Y X.
In other words, little ad of X applied to Y equals X bracket Y Note that this makes sense even without reference to G.
Exercise:
Since little ad equals capital Ad star we know already that it's a representation of Lie algebras, but it's possible to prove it directly from the axioms of a Lie algebra without reference to the group G i.e. that little ad of X bracket Y applied to Z equals little ad of X times little ad of Y applied to Z minus little ad of Y times little ad of X applied to Z for all X, Y, and Z in little g. Do this!
Example: sl(2,C)
Recall that we have a basis H, X, Y for little s l 2 C. Let's compute little ad H with respect to this basis.
little ad H sends:
H to H bracket H, which equals 0,
X to H bracket X, which equals 2 X,
Y to H bracket Y, which equals minus 2 Y,
so little ad H is the diagonal matrix with diagonal entries 0, 2, minus 2 with respect to this basis.
In fact, the action of H on a representation tells us the weights, so we see that the weights of the adjoint representation are minus 2, 0, and 2. In particular, the adjoint representation is isomorphic to Sym 2 C 2.
It's an exercise to compute little ad X and little ad Y.
Example: sl(3,C)
Let's find a basis of little s l 3 C. Define E_{i j} to be the matrix with zeros everywhere except in position i, j where there is a 1, e.g. E_(1 2) is the 3-by-3 matrix 0, 1, 0; 0, 0, 0; 0, 0, 0 There are 6 such matrices with i not equal to j. Together with H_(1 3) equals 1, 0 ,0; 0, 0, 0; 0, 0, -1 and H_(2 3) equals 0, 0, 0; 0, 1, 0; 0, 0, minus 1, this gives us a basis of little s l 3 C; in other words, any tracefree complex matrix can be written as a complex linear combination of these 8 (it's an 8-dimensional Lie algebra).
More generally, we will write H theta for the diagonal matrix in little s l 3 C with diagonal entries theta_1, theta_2, theta_3 where theta equals (theta_1, theta_2, theta_3) is a vector satisfying theta_1 plus theta_2 plus theta_3 equals 0 I want to compute little ad of H_theta.
We have little ad H_(theta) H_(i j) equals 0 because the H-matrices are all diagonal (and hence all commute with one another). This means that H_{1 3} and H_{2 3} are contained in the zero-weight space of the adjoint representation. This is because exp of i H_(theta) equals the diagonal matrix with diagonal entries e to the i theta_1, e to the i theta_2, e to the minus i (theta_1 plus theta_2), so the eigenvalues of H_(theta) tell us the weights of the representation.
It turns out that little ad of H_(theta) applied to E_(i j) equals (theta_i minus theta_j) times E_(i j). For example: H_(theta) bracket E_(i j) equals theta_1, 0, 0; 0, theta_2, 0; 0, 0, minus theta_1 minus theta_2 bracket 0, 1, 0; 0, 0, 0; 0, 0, 0; which equals 0, theta_1, 0; 0, 0, 0; 0, 0, 0; minus 0, theta_2, 0; 0, 0, 0; 0, 0, 0; which equals (theta_1 minus theta_2) times E_(1 2)
Let's figure out the weights of the adjoint representation. If v in W_(k l) then we have exp of i little ad H_(theta) equals e to the i (k theta_1 plus l theta_2) times v, so little ad of H theta applied to v equals (k theta_1 plus l theta_2) times v. For example, E_{1 2} satisies little ad H_(theta) applied to E_(1 2) equals (theta_1 minus theta_2) times E_(1 2), so E_(1 2) is in W_(1, minus 1).
Similarly, we get little ad H_(theta) E_(1 3) equals (theta_1 minus theta_3) E_(1 3), which equals ((2 theta_1) plus theta_2) times E_(1 3), so E_(1 3) is in W_(2, 1).
Exercise:
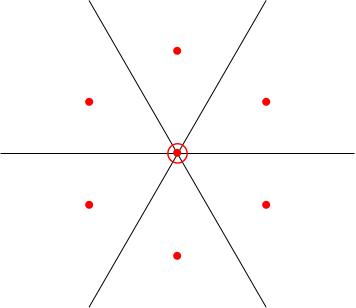
The other weight space that occur are: E_(1 2) in W_(1, minus 1); E_(2 1) in W_(minus 1, 1); E_(1 3) in W_(2 1); E_(3 1) in W_(minus 2, minus 1); E_(2 3) in W_(1 2); and E_(3 1) in W_(minus 1, minus 2) and the weight diagram is the hexagon shown in the figure below.
Note that the zero-weight space is spanned by H_{1 3} and H_{2 3}, which means it's 2-dimensional. We've denoted this by putting a circle around the dot at the origin in the weight diagram.
Remark:
The weight space decomposition of the adjoint representation is sufficiently important to warrant its own name: it's called the root space decomposition. The weights that occur are called roots and the weight diagram is called a root diagram.
Pre-class exercise
Exercise:
The matrices E_{i j} inhabit the following weight spaces: E_(1 2) in W_(1, minus 1); E_(2 1) in W_(minus 1, 1); E_(1 3) in W_(2 1); E_(3 1) in W_(minus 2, minus 1); E_(2 3) in W_(1 2); and E_(3 1) in W_(minus 1, minus 2) and the weight diagram is the hexagon shown above.